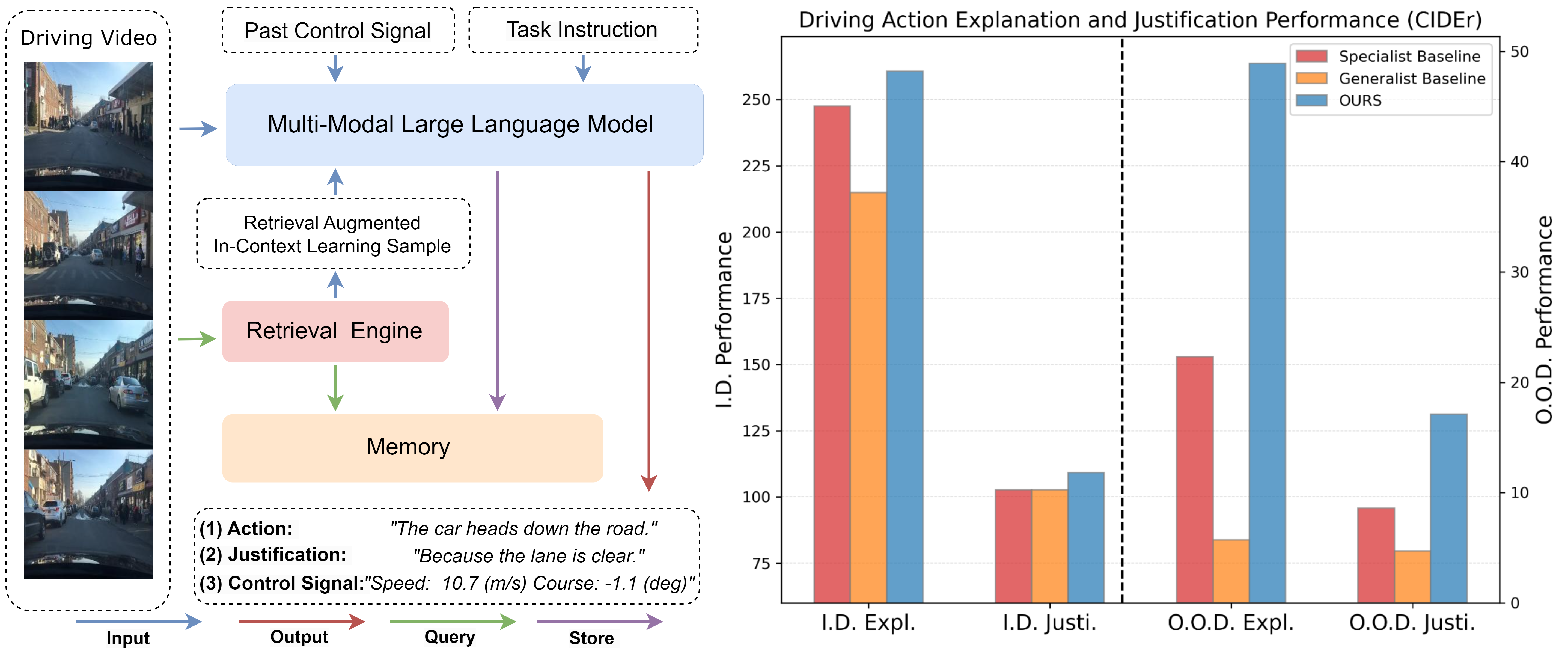
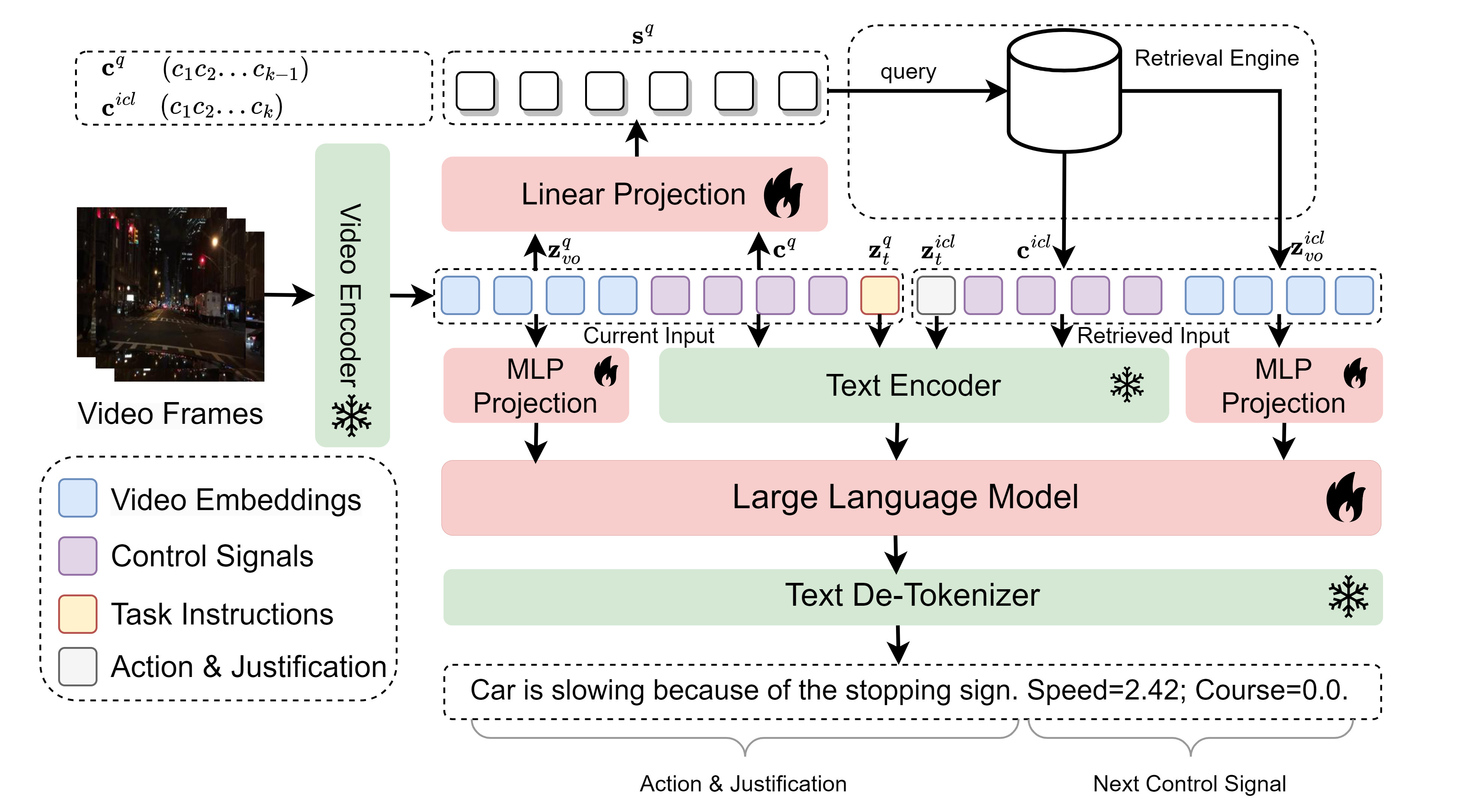
We need to trust robots that use often opaque AI methods. They need to explain themselves to us, and we need to trust their explanation. In this regard, explainability plays a critical role in trustworthy autonomous decision-making to foster transparency and acceptance among end users, especially in complex autonomous driving. Recent advancements in Multi-Modal Large Language models (MLLMs) have shown promising potential in enhancing the explainability as a driving agent producing control predictions along with natural language explanations. However, severe data scarcity due to expensive annotation costs and significant domain gaps between different datasets makes the development of a robust and generalisable system an extremely challenging task. Moreover, the prohibitively expensive training requirements of MLLM and the unsolved problem of catastrophic forgetting further limit their generalisability post-deployment.To address these challenges, we present RAG-Driver, a novel retrieval-augmented multi-modal large language model that leverages in-context learning for high-performance, explainable, and generalisable autonomous driving. By grounding in retrieved expert demonstration, we empirically validate that RAG-Driver achieves state-of-the-art performance in producing driving action explanations, justifications, and control signal prediction. More importantly, it exhibits exceptional zero-shot generalisation capabilities to unseen environments without further training endeavours.